A virtual model is a named entry in TrueFoundry AI Gateway that your application calls like any other model (for exampleDocumentation Index
Fetch the complete documentation index at: https://www.truefoundry.com/llms.txt
Use this file to discover all available pages before exploring further.
my-group/production-chat). Behind that name, you configure one routing strategy and one or more real target models (for example azure/gpt-4o and openai/gpt-4o). The gateway handles load balancing, health-aware routing, retries, and fallbacks automatically so you do not hard-code provider details in every service.
Why route across multiple targets?
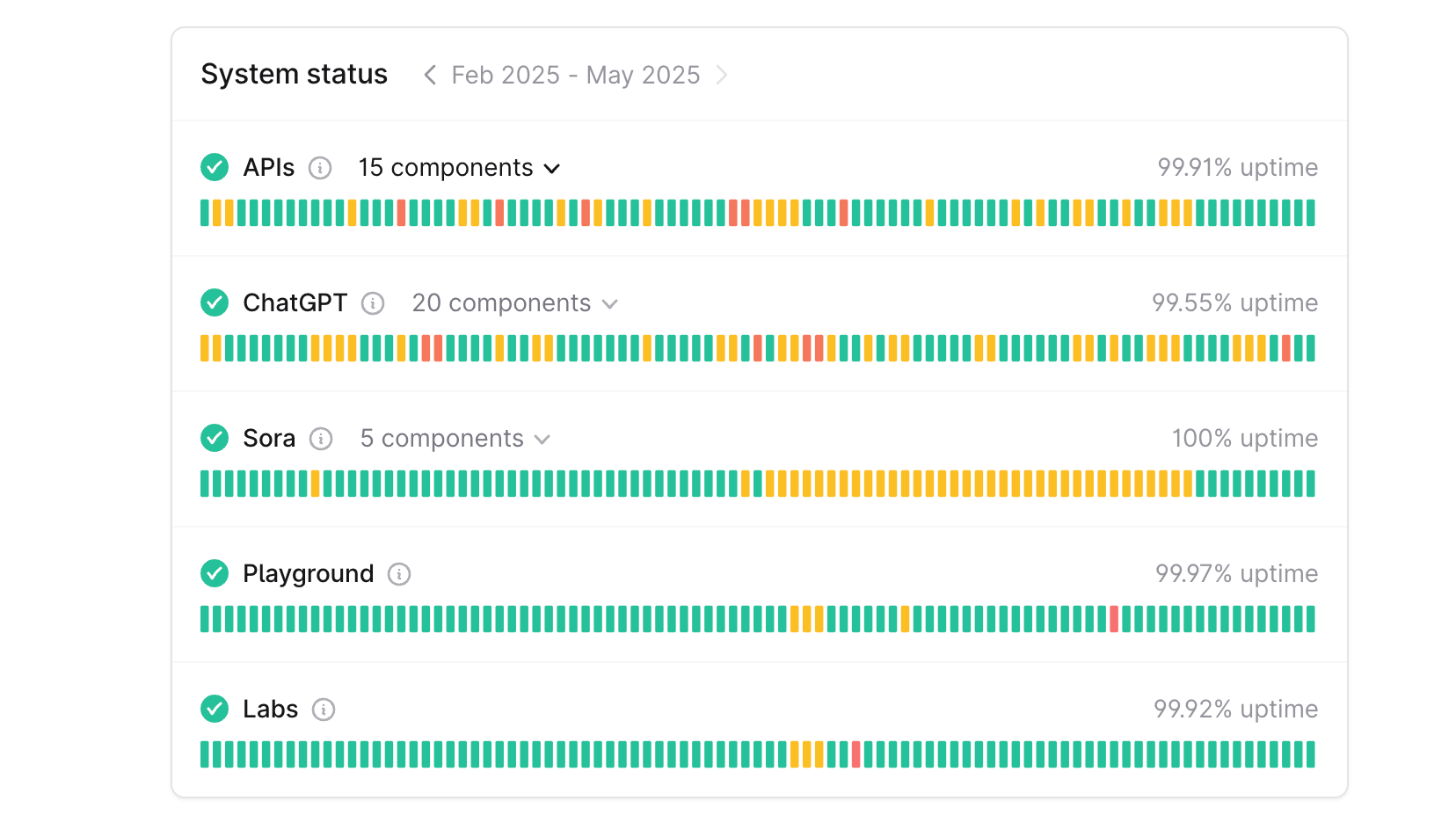
Production LLM traffic benefits when the gateway can choose or fail over among more than one backend. Common drivers:Service outages and downtime
Service outages and downtime
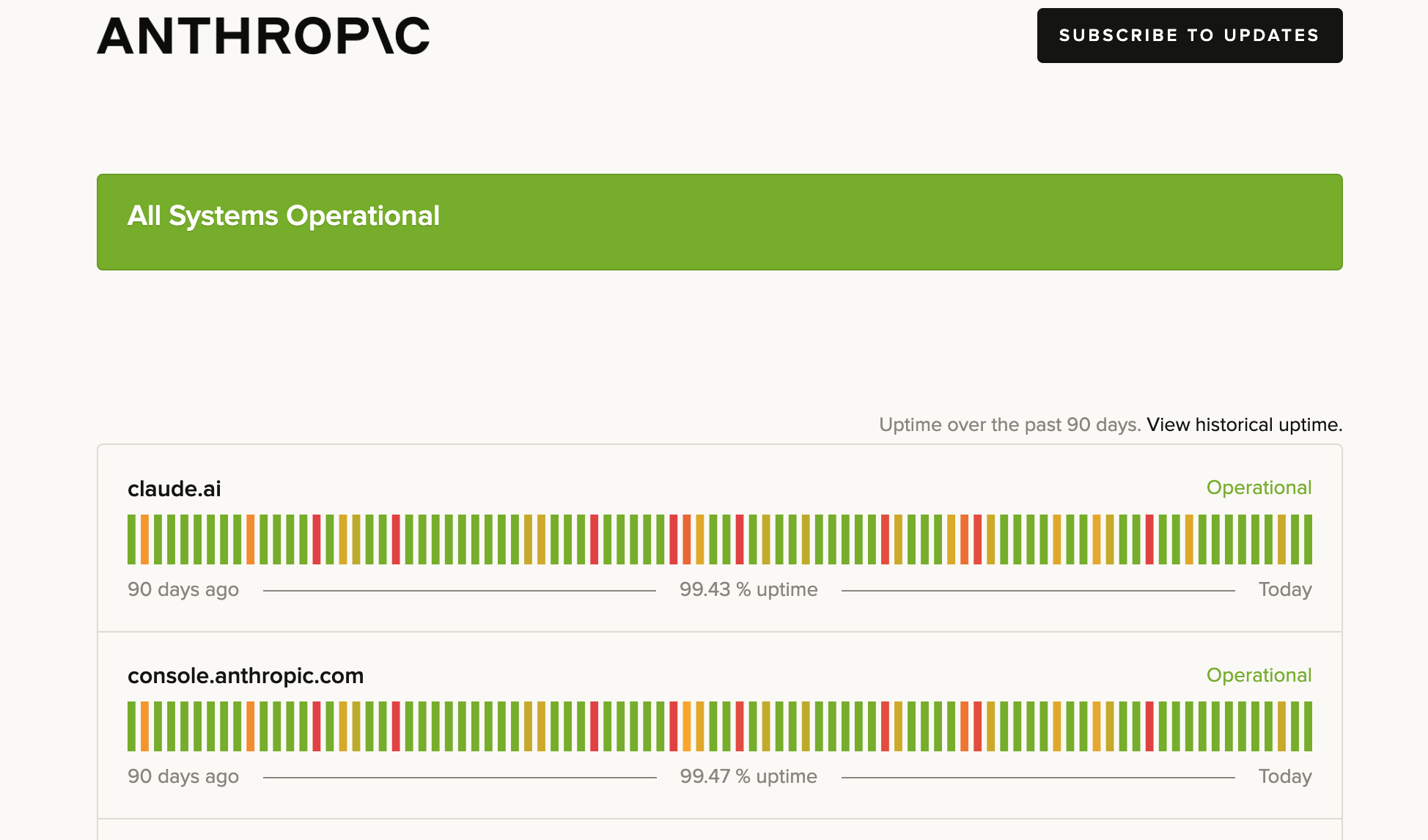
Latency variance among models
Latency variance among models
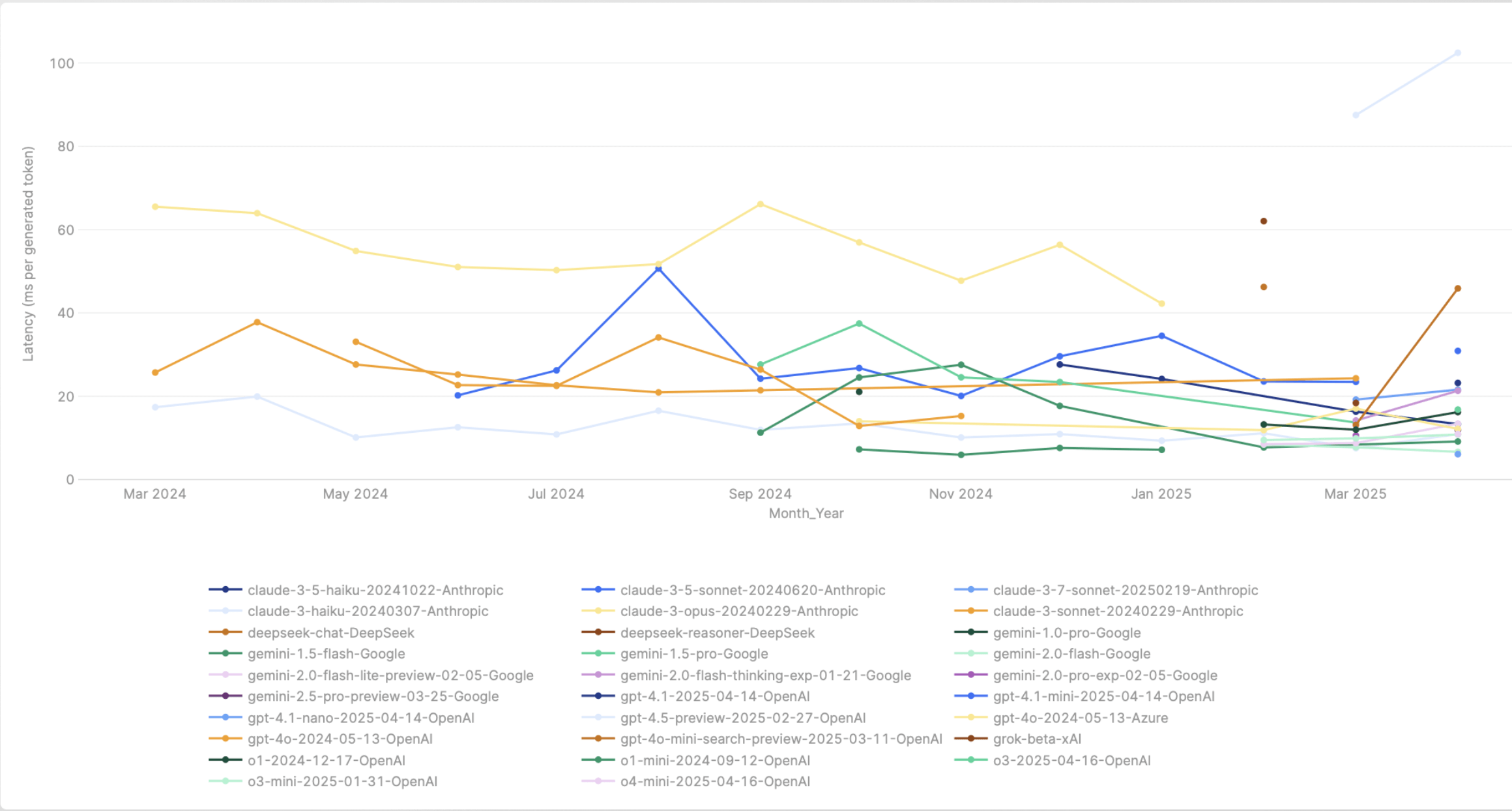
Rate limits of models
Rate limits of models
Canary testing
Canary testing
Why virtual models?
- Stable API surface — Your apps pass one model identifier; you change targets, weights, or providers in the gateway without redeploying clients.
- Resilience — Retries and fallback status codes route around rate limits and transient errors across targets.
- Governance — Virtual model provider groups support collaborator roles so teams can use or manage routing separately.
Routing strategies
When you create a virtual model, you choose one of three routing strategies. Each strategy uses the same list of targets; the difference is how the gateway picks among healthy targets for each request.| Strategy | How it works | Best for |
|---|---|---|
| Weight-based | Distributes traffic by assigned weights (e.g. 80/20). Also supports sticky routing to pin sessions to a target. | Canary rollouts, fixed capacity splits, A/B allocation |
| Priority-based | Routes to the highest-priority healthy target (0 = highest). Falls back to the next on failure. Supports SLA cutoff. | Primary + backup topologies, cost optimization |
| Latency-based | Automatically routes to the target with the lowest recent latency. No weights needed. | Performance chasing across regions or providers |
Weight-based routing
You assign a weight to each target. The gateway distributes incoming requests in proportion to those weights. For example, 90% toazure/gpt-4o and 10% to openai/gpt-4o.
Sticky routing (weight-based only)
Sticky routing pins requests that share the same session key to the same target model for a configurable time window (ttl_seconds). Within that window, every request carrying the same session identifier is routed to the same model. When the window expires, the session is re-evaluated and may land on a different model. Useful for multi-turn conversations, prompt cache efficiency, and consistent user experience.
Configuring sticky routing
Configuring sticky routing
sticky_routing block inside your weight-based routing configuration. Two fields are required: ttl_seconds and at least one entry in session_identifiers.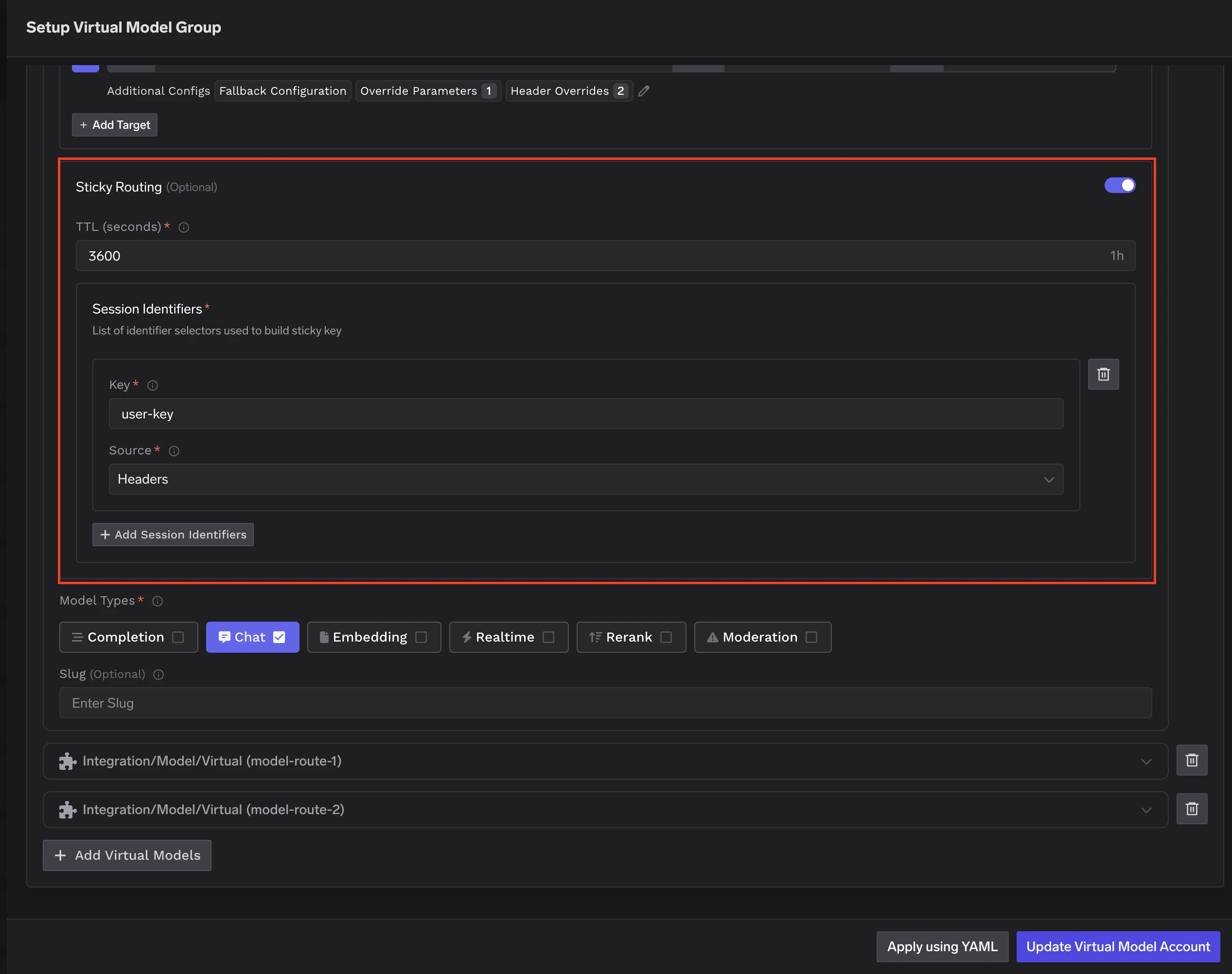
key— The header or metadata field name to read.source—headersto read from HTTP request headers, ormetadatato read from request metadata.
ttl_seconds defines how long a session stays pinned. For chatbots, 3600 (1 hour) is a common starting point. For longer workflows, consider 86400 (24 hours).Fallback during a sticky session: If the pinned model fails, the remaining healthy targets are tried in sequence (this fallback order is not weight-based). Only targets with fallback_candidate: true are eligible. After a successful fallback, subsequent requests for that session in the same TTL window are routed to the working target — not back to the one that failed.Priority-based routing
Each target has a priority number. The gateway routes to the highest priority target (0 is highest) that is healthy. If that target fails or is unavailable, the gateway falls back to the next.SLA cutoff
SLA cutoff
- Configure a Time Per Output Token (TPOT) threshold per target using
sla_cutoff.time_per_output_token_ms - The gateway monitors average TPOT over a 3-minute rolling window (up to 10 samples, minimum 3 required)
- If TPOT exceeds the threshold, the target is marked unhealthy and moved to the end of the list
- Recovery is automatic when metrics improve or older data ages out
Latency-based routing
You do not set weights. The gateway chooses the target with the lowest recent latency automatically.How latency is measured
How latency is measured
- Only requests in the last 20 minutes are considered. If more than 100 requests exist in that window, the last 100 are used. If fewer than 3 requests exist, the model is treated as the fastest so that more traffic is routed to it to gather data.
- Models are considered equally fast if their TPOT is within 1.2× of the fastest — this avoids rapid switching due to minor differences.
Configuration structure
The following YAML shows the complete shape of a virtual model’s routing configuration with all available fields. In the dashboard UI, the same fields are set through the form editor.Key fields
type — The routing strategy for this virtual model:
weight-based-routing— Distribute traffic by assigned weights that sum to 100.latency-based-routing— Automatically route to the target with the lowest recent latency. No weights needed.priority-based-routing— Route to the highest priority (lowest number) healthy target, falling back to the next on failure.
load_balance_targets — The list of real models eligible for routing. Each target and its configuration options are described in detail in the Per-target configuration section below.
Per-target configuration
Regardless of which routing strategy you choose, each target in the virtual model supports several options that control what happens when a request is routed to that target.Retries and fallbacks
Each target can define how the gateway should handle failures before giving up or moving to another target:- Retry configuration — Number of attempts, delay between retries, and which status codes trigger a retry on the same target. Defaults: 2 attempts, 100 ms delay, retry on
429,500,502,503. - Fallback status codes — Which status codes cause the gateway to stop retrying this target and try a different target instead. Default:
401,403,404,429,500,502,503. - Fallback candidate — Whether this target is eligible to receive traffic when another target fails. Default:
true. Set tofalsewhen you want a target to be used only as a primary and never receive fallback traffic from other targets.
Retry and fallback example
Retry and fallback example
- A request first goes to
azure/gpt-4o(priority 0). If it returns429, the gateway retries up to 3 times with 200 ms delay. If retries are exhausted or a fallback status code is returned, it falls back to the next target. openai/gpt-4o(priority 1) is tried next with its own retry config.anthropic/claude-sonnet(priority 2) hasfallback_candidate: false, so it is never tried as a fallback for the other two targets — it is only used when it is itself the highest-priority healthy target.
Header overrides
You can inject or remove HTTP headers on a per-target basis, applied just before the request is sent to that model. This is useful when a specific target requires headers that the others don’t — for example, a region identifier, a deployment ID, or an API version header expected by one provider but not the rest.Configuration and examples
Configuration and examples
headers_override block to any target in your load_balance_targets list: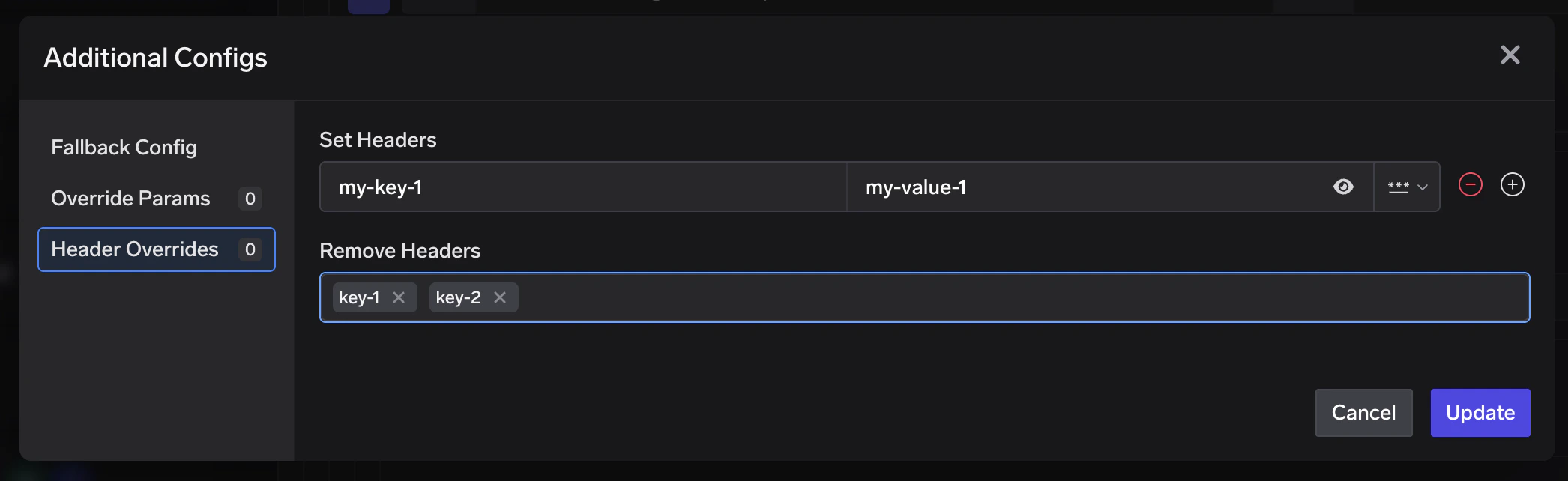
set— Key-value pairs of headers to add or overwrite on the outgoing request.remove— List of header keys to strip from the outgoing request.
X-Custom-Auth and x-custom-auth refer to the same header. The gateway normalises all keys to lowercase before applying overrides. Header overrides are applied last, after parameter overrides, so they reflect the final outgoing headers sent to the provider.Metadata-based target filtering
You can constrain a target to only receive traffic when request metadata matches specific key-value pairs usingmetadata_match.
The gateway evaluates resolved metadata (not just raw request headers). Metadata can come from:
- Request metadata header —
x-tfy-metadata(JSON object with string keys and values) - Virtual account tags — when using a virtual account, its tags are included in metadata
- Default gateway metadata — configured at gateway level (commonly used in self-hosted setups)
- SaaS gateway location metadata —
tfy_gateway_regionandtfy_gateway_zoneare automatically added by the SaaS gateway based on which region handled the request
- request metadata
- default gateway metadata (overrides request value for overlapping keys)
- virtual account tags (highest precedence)
- If
metadata_matchis not set (or empty), that target always stays eligible. - If
metadata_matchis set, all configured pairs must match exactly (ANDsemantics). - Filtering happens before load-balancing order and sticky routing are computed, so only matching targets participate in routing for that request.
Basic metadata filtering
Basic metadata filtering
openai/gpt-4o remains eligible because the first target does not match.SaaS gateway region-based routing
SaaS gateway region-based routing
tfy_gateway_region and tfy_gateway_zone based on which gateway handled it. You can use metadata_match to route traffic from specific regions to region-appropriate model deployments — without the client needing to send any metadata.- A user in the US hits
gateway.truefoundry.ai, which routes to the nearest US gateway. The gateway automatically setstfy_gateway_region: USin resolved metadata, so the request matchesazure-us/gpt-4o. - A user in Europe hits the nearest EU gateway (
tfy_gateway_region: EU), matchingazure-eu/gpt-4o. - A user in India hits the nearest India gateway (
tfy_gateway_region: IN), matchingazure-in/gpt-4o. - Users from any other region (e.g. Australia, South America) don’t match any
metadata_matchrule, so they fall through toopenai/gpt-4o(priority 1) which has nometadata_matchand acts as the default.
Model-specific prompt overrides
When a virtual model sends traffic to targets from different model families, you may need different prompt versions per provider. Configureprompt_version_fqn in override parameters on each target. When a request is routed to a target, the gateway uses that target’s prompt version for hydration.
When and how to use prompt overrides
When and how to use prompt overrides
- Different models require different prompt formats or structures
- You want to optimize prompts for specific model capabilities
- You need to maintain model-specific prompt versions behind one virtual model name
prompt_version_fqn override does not work with agents (when using MCP/tools). It is supported for standard chat completion requests.Unhealthy target detection
All the routing strategies described above only consider healthy targets when deciding where to send a request. The gateway continuously monitors every target and automatically marks targets as unhealthy when they start failing or breaching performance thresholds. This section explains how that health tracking works. When a target is marked unhealthy, healthy targets are always tried first. Unhealthy targets are moved to the end of the list and only used as a last resort if all healthy targets fail. Recovery is automatic once errors age out of the evaluation window.Failure-based cooldown (all routing types)
Failure-based cooldown (all routing types)
- Error responses considered:
5xx,429,401, and403 - Default failure threshold:
2or more failures - Default evaluation window: last
2minutes (rolling window) - Recovery: automatic, once failures age out of the window
SLA-based cooldown (priority-based routing only)
SLA-based cooldown (priority-based routing only)
sla_cutoff.time_per_output_token_ms. If the average TPOT over a 3-minute rolling window exceeds the configured threshold (with at least 3 samples), the target is marked unhealthy. See SLA cutoff above.FAQ
Can I change the routing strategy after creating a virtual model?
Can I change the routing strategy after creating a virtual model?
How do I know which target handled a request?
How do I know which target handled a request?
x-tfy-resolved-model response header. This may differ from the virtual model you requested due to load balancing or fallbacks. You can also view per-target traffic, success rates, and latency in the AI Gateway dashboard.Can one virtual model support several API types (chat and embedding)?
Can one virtual model support several API types (chat and embedding)?
What if every target fails?
What if every target fails?
Can a virtual model point to another virtual model as a target?
Can a virtual model point to another virtual model as a target?
Can I use sticky routing with latency-based or priority-based routing?
Can I use sticky routing with latency-based or priority-based routing?
Will the same session always go to the same model forever?
Will the same session always go to the same model forever?
ttl_seconds window. Once the window expires, the session is re-evaluated and may land on a different model. Size ttl_seconds to match your typical session duration.Will sticky routing work if my gateway has multiple pods?
Will sticky routing work if my gateway has multiple pods?
Do header overrides affect all targets or just the one I configure them on?
Do header overrides affect all targets or just the one I configure them on?
How does metadata matching work across multiple keys?
How does metadata matching work across multiple keys?
metadata_match uses all-keys-must-match logic for a target. If you configure multiple keys, every key-value pair must match request metadata exactly for that target to be eligible.What if I set metadata rules on some targets but not others?
What if I set metadata rules on some targets but not others?
metadata_match remain eligible for all requests and act as a default path. Targets with metadata_match are included only when their conditions match.How does metadata filtering interact with sticky routing and fallback?
How does metadata filtering interact with sticky routing and fallback?