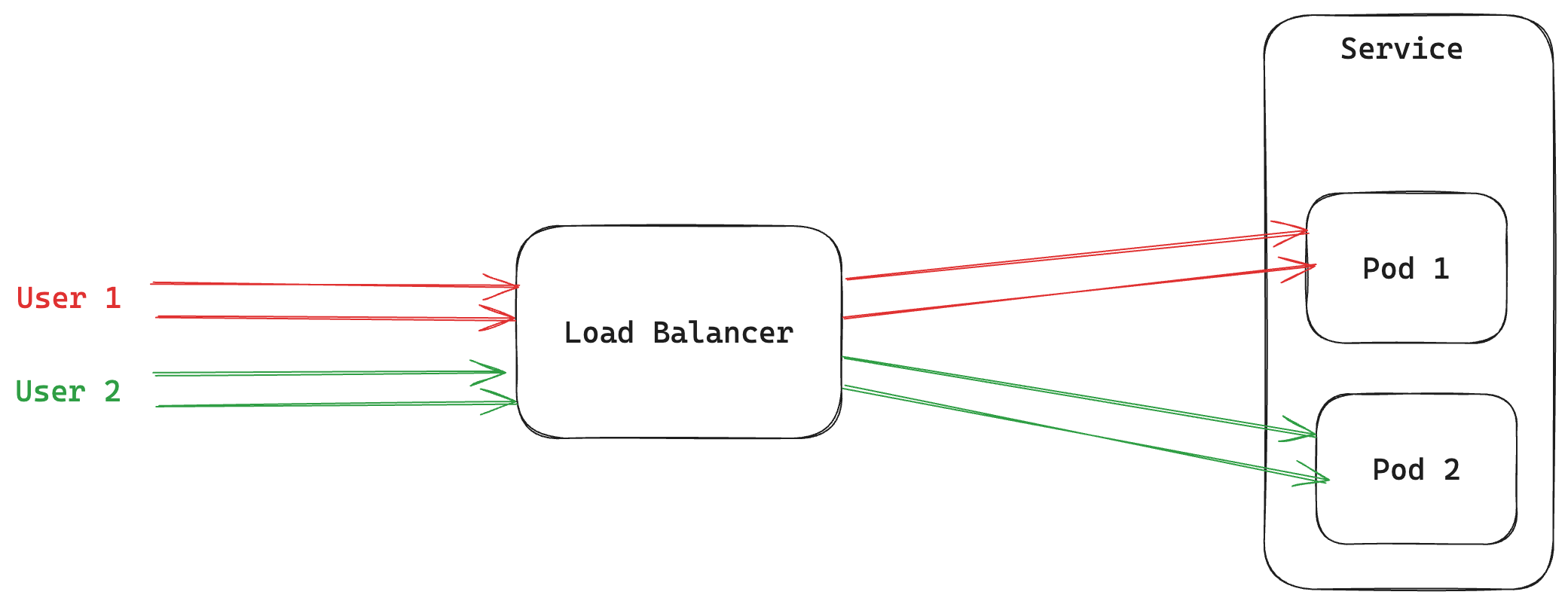
Imagine a situation where a user is performing some expensive calculation in a request and wants to do so repeatedly over a bunch of API calls. Some of these expensive calculations might have some common computation that you might want to cache between requests. In such a case, you would like to route all the requests from a specific user to a specific replica. One such example is Prefix Caching with model servers like vLLM and SGLang where generating the next reply in a converstation can benefit from the cached computation of the conversation history so far and result in significantly lower latencies.Documentation Index
Fetch the complete documentation index at: https://www.truefoundry.com/llms.txt
Use this file to discover all available pages before exploring further.
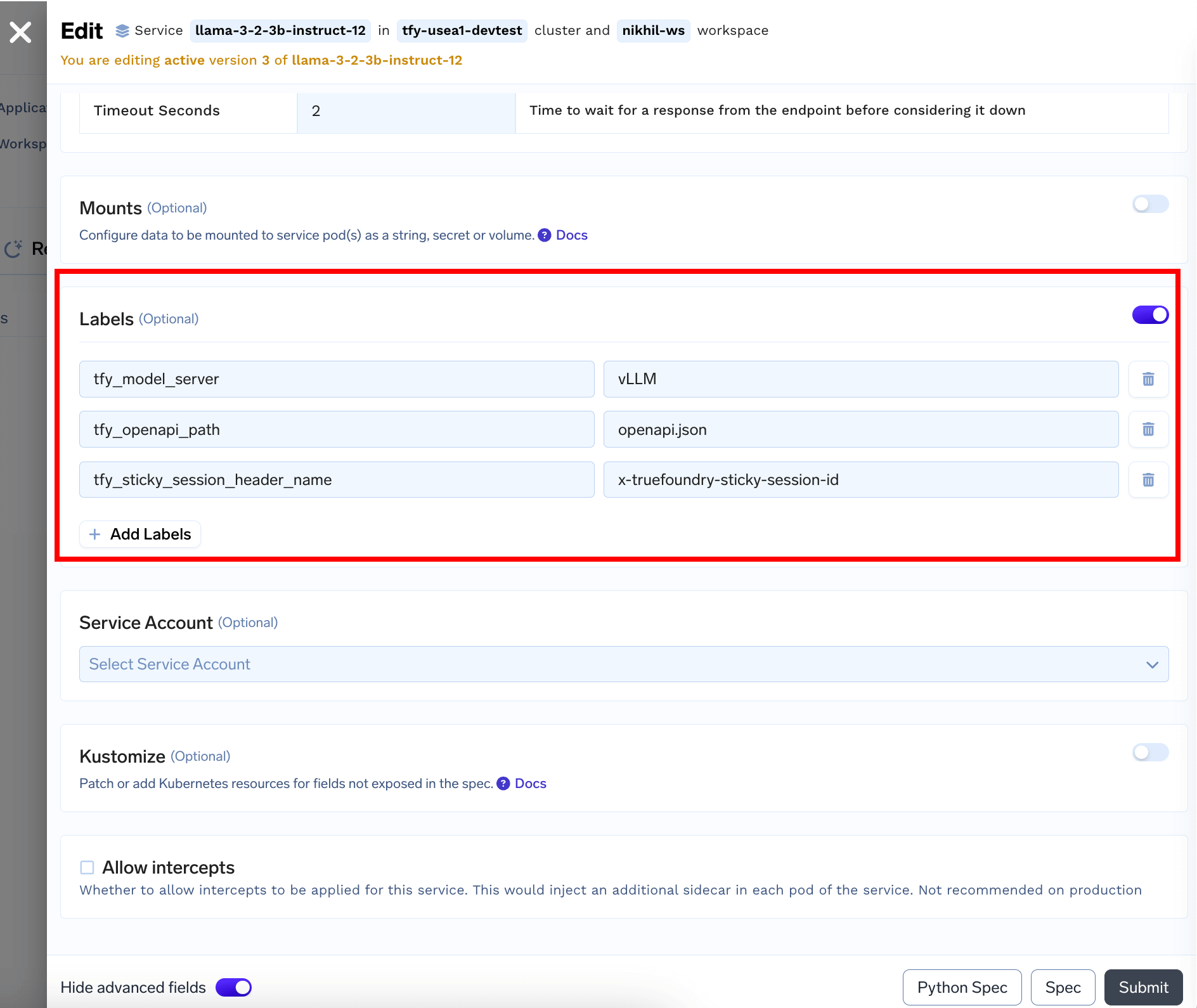
Enabling Sticky Routing
To enable sticky routing, first in the Servicelabels section add a special label tfy_sticky_session_header_nameand add a header name against it. For e.g. x-truefoundry-sticky-session-id
Passing the header when making requests
Now, your clients can send this header with a unique value for a “session”. For e.g. this value can be a conversation id or user id, anything that identifies a unique session that can benefit from stickyness. For e.g.x-truefoundry-sticky-session-id: session-id-qnfjk will be routed to the same pod the first request was routed to.